Documentation is a love letter that your write to your future self.
Damian Conway
We are proud to welcome Bhumit Attarde to STE||AR Group as the new technical writer that will work with us during this year’s Google Season of Docs period. Bhumit will focus on developing additional content for our HPX documentation in order to aid prospective users to navigate easier through our codebase. We are looking forward to a fruitful collaboration that will benefit our open source community and enrich our impact in the world of High Performance Computing.
STE||AR Group was accepted for Google Season of Docs 2022! We look forward to developing our HPX documentation even more and expanding our group this summer.
Like Google Summer of Code (GSoC) the program aims to match motivated people with interesting open source projects that are looking for volunteer contributions. GSoD, however, aims to improve open source project documentation, which often tends to get less attention than the code itself.
We are now looking for motivated people to help us improve our documentation. If you have some prior experience with technical writing, and are interested in working together with us on making the documentation of a cutting edge open source C++ library the best possible guide for new and experienced users, this is your chance. You can read more about the program on the official GSoD home page. We’ve provided a few project ideas on our wiki, but you can also come up with your own. Our current documentation can be found here.
The STE||AR Group is honored to be selected as one of the 2022 Google Summer of Code (GSoC) mentor organizations! This program, which pays students over the summer to work on open source projects, has been a wonderful experience for students and mentors alike. This is our 8th summer being accepted by the program!
Interested students can find out more about the details of the program on GSoC’s official website. As a mentor organization we have come up with a list of suggested topics for students to work on, however, any student can write a proposal about any topic they are interested. We find that students who engage with us on IRC (#ste||ar on freenode) or via our mailing list hpx-users@stellar-group.org have a better chance of having their proposals accepted and a better understanding of their project scope. Students may also read through our hints for successful proposals.
If you are interested in working with an international team of developers on the cutting edge of C++ parallel, task-based runtime systems please check us out!
Vectorization is a technique to allow incore parallelism using CPU vector registors which enables us to exploit data-parallelism. Recent additions in C++17 and C++20 to parallel algorithms accept execution policy as first argument which changes the execution behaviour based on the given policy. We implement two new execution policies hpx::execution::simd and hpx::execution::par_simd. The former policy does execution in sequential fashion with Vectorization added, where as the latter one does execution in parallel with Vectorization. For both of these newly implemented policies, the iterator function now no longer accepts static types instead accept only generic types i.e templated or generic function objects. This allows the function object to work with both non-simd and simd policies with a very little or no change in the code. We used std::experimental::simd (_available in C++20 with GCC >= 11.1 and Clang >= 12) as the Vectorization backend in implementing the 2 new execution policies. In the following sections we dicuss example codes on how to use these new facilites adapted to hpx and the benchmarks with results performed on various architectures using different kernels.
Example Usage
The following example code snippet describes the use of hpx for_each algorithm with different execuction policies such as seq, par, simd and par_simd.
Note that we passed a generic lambda to for_each algorithm as argument because the same lambda can be used with different execution policies. The template argument ExPolicy is used to accept execution policy, T is used for handling data-types for creating std::vector and Gen is used to accept geneartor function to fill the std::vector. If the execution policy is seq or par then variable x would be of arithmetic typeT as int, float and so on.. where as if execution policy is simd or par_simd then x would of type std::experimental::simd<T> as std::experimental::simd<int>, std::experimental::simd<float> and so on. std::experimental::simd<T> is a vector_pack of type T which is value_type of iterator nums. Contigous elements of the iterator are loaded internally into the vector_pack. The sin and cos functions in the lambda are adapted to arithmetic types and vector_pack types (available in std::experimental namespace).
The lambda used in this code snippet is a compute-bound kernel because of high Arithmetic Intensity due to loop running for 100 steps performing sin and cos operations at each step.
Now, we look into another example using a memory bound kernel (performing SAXPY Operation) with help of transform algorithm.
This code snippet is very similar to the previous with change in lambda and algorithm. Here as well, the arguments to lambda is of two types either arithmetic type (if execution policy is seq or par), or vector_pack type (if the execution policy is simd or par_simd).
The following code snippet describes the usage of algorithms such as count, find. These do not require any lambda and hence vectorization is straightforward just with implementation itself.
This class of algorithms is much easier and are more prone to getting vectorized because of minimum intervention with users i.e no lamda or function is taken in the arguments. Note that we get vectorization benefits only if the iterators passed to algorithm are random access iterators.
Example Implementation
The above code snippet shows implementation for datapar_loop function, which is main vectorization backend helper function for most of the iterative algorithms in hpx. The function call in datapar_loop class can be divided into 3 main steps.
First a prefix loop runs the code in sequential fashion by calling each element with function f using the helper function datapar_loop_step::call1. This loop runs until it finds first aligned element.
Secondly, the main vectorization loop, where actual vectorization happens with datapar_loop_step::callv function which actually creates a vector_pack then loads the elements from iterator and calls the function f and then stores back the results as below.
Finally, the last block i.e post-fix loops handles the elements at the end of array or container that are less than vector_pack size and hence cannot be fit into single vector_pack. So they are handled in sequential fashion similar to pre-fix loop.
Benchmarks
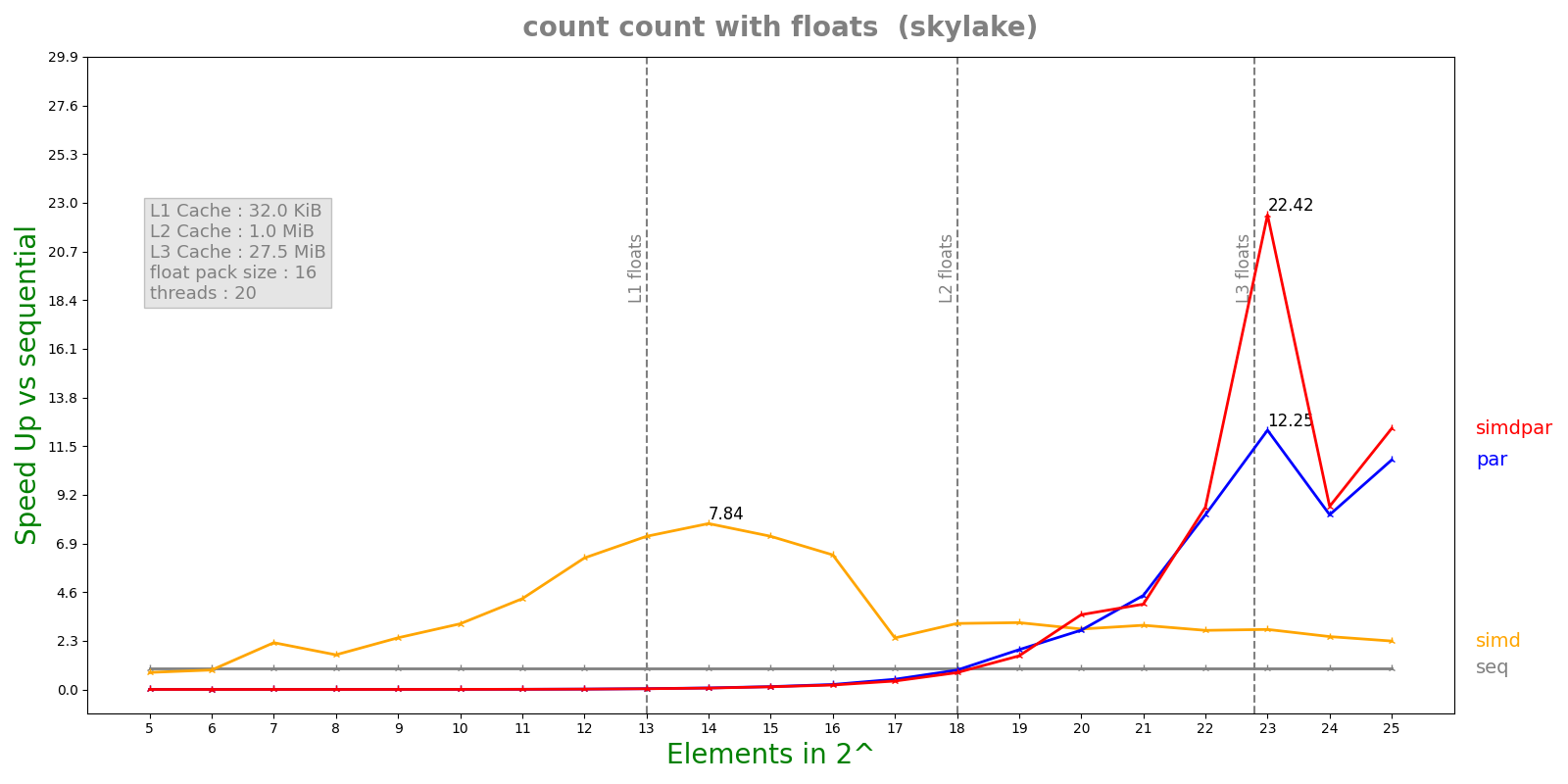
We ran the benchmarks for 2 classes of algorithms. First class being iterative algorithms where each element from the iterator gets mapped using some function. We used for_each and transform algorithms with compute bound and memory bound kernels. For the second class of algorithms, we pick the algorithms which have consists of conditional statements and these can be called as algorithms with simd mask reductions. For this class, we chose count and find algorithms.
Results
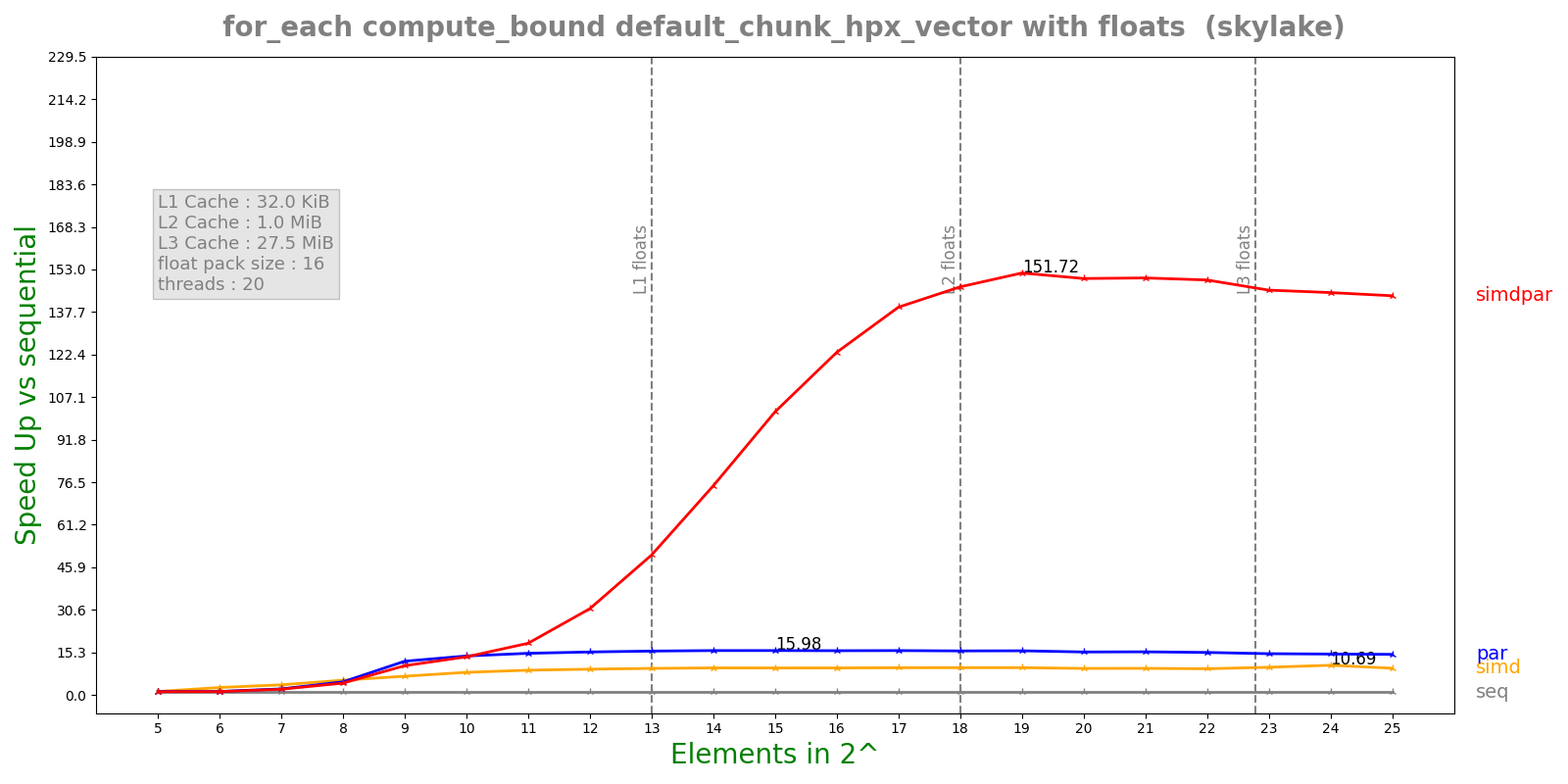
The Following figure shows benchmark of for_each algorithm with compute bound kernel i.e Example 1. These benchmarks were run on Intel Xeon Skylake with AVX512. AVX512 vector register can hold 16 floating point elements. We can see a 12x speed up with simd policy and over 140x with par_simd.
The above image shows the benchmark results graph depeciting speed ups of simd, par and par_simd against seq execution policy. These benchmarks were run on AMD EPYC 7H12 with AVX2. AVX2 vector register can hold 8 floating point elements.The array used contains 128 Billion elements with float and double as data types. We can see super-linear scaling for simd speed up in compute bound kernels i.e speed up of simd (10.37) is more than vector_pack size (8) because sin and cos implementations for scalar arithmetic types and vector_pack types are slightly different. We can see a 3 order magnitude of speed up when using par_simd execution policy.
Conclusion
From the examples illustrated and the benchmarks, we can see how easy it is to vectorize the code using simd and par_simd execution policies and gain massive speed ups with very little change in code. Currently adapting algorithms to simd and par_simd policies is still under progress. You can find the list of algorithms adapted to these policies .
Nikunj Gupta, a STE||AR Group GSoC student from 2018 and continued collaborator with our group, has received a Thesis Award from his University, IIT Roorkee, based on his research.
IIT Roorkee allows students to pursue research in foreign universities (Foreign BTP), wherein the student should have 1 supervisor (IIT Roorkee Prof) and 1 co-supervisor, the professor under which the student pursues research. Dr. Hartmut Kaiser introduced Nikunj to Prof. Sanjay Laxmikant V. Kale, at the University of Illinois at Urbana-Champaign for the purposes of this project. Dr. Kale interviewed Nikunj and agreed to provide a research internship from Sept-Dec. Nikunj proposed this research as Foreign BTP to his University and was accepted.
After completion of his research internship, Nikunj received an award for his project during his University’s Convocation Ceremony held on Sept 11, 2021.
The details of the project, provided by Nikunj, and are below. Congratulations, Nikunj! We are proud of the work you do.
Sept-Dec:
I worked with Sanjay on part 1 of my thesis, which was to write abstractions over Charm++ to generate a linear algebra library. The salient features of this library were out-of-order execution, completely asynchronous operations and almost linear distributed scaling. As a future work, I decided to optimize the library (something I’m doing right now as a graduate student here at UIUC) and to generate a frontend language that has a MATLAB like syntax.
Jan-June:
I felt that I could add more to my thesis to make it stronger, so I decided to add my resilience work to it. I contacted Hartmut regarding resiliency work to which he agreed. The work was to implement resilience execution spaces in Kokkos. I created Kokkos executors for HPX to use Kokkos facilities to achieve resilience within HPX and also added resilience execution spaces in Kokkos to achieve resilience within Kokkos. The resilience scheme within Kokkos is an auto-generative scheme that will work with all current and future execution spaces. I also included my past work with resilience in my thesis. So, the work I did back in Summer 2019 and Summer 2020 was included in my thesis too. In Summer 2019, I worked on implementing Local-Only Software Resilience in HPX which I extended to Distributed Software Resilience in Summer 2020. The resilience work has also been published last year at the FTXS workshop in Supercomputing titled “Towards distributed software resilience in asynchronous many-task programming models”. We plan on writing a paper on the Kokkos resilient execution space as well!
Nanmiao Wu is a Ph.D. student In the Department of Electrical and Computer Engineering and Center for Computation and Technology, LSU. She has been working in STE||AR group for more than 2 years and is co-advised by Dr. Hartmut Kaiser, head of the STE||AR Group, and Dr. Ram Ramanujam, Director of CCT.
Before joining LSU, she received a B.S. degree in Electronic Information Science and Technology from Nankai University, and an M.S. degree in Electrical and Computer Engineering from the University of Macau.
Nanmiao’s research focuses on scalable and distributed high-performance computation for machine learning and deep learning applications.
She has been an intern at Pacific Northwest National Laboratory (PNNL) from February to August 2021, developing a HPX runtime interface for a C++ algorithm and data-structure library, SHAD, for better scalability and performance. The linear scaling performance is achieved on a single locality with varying data-structure sizes and on multiple localities. During the internship, she has utilized the HPX serialization library to bitwise serialize SHAD types. She also learned how to associate multiple tasks to the same handle, forming a task group, and run the callbacks on remote localities via customized actions.
Before that, she collaborated with PNNL for a scalable second-order optimization for deep learning applications. During the collaboration, she has implemented a PyTorch second-order optimizer and compared its performance with stochastic gradient descent (SGD), a first-order optimizer, on an image classification task, using a multi-layer perceptron network with one hidden layer. The scalable performance and improving throughput were achieved: 2.2x speedup was achieved over SGD in multi-thread scenario, and 5.8x speedup was achieved in multi-process scenario.
Previously, she implemented a scalable and distributed alternating least square (ALS) recommendation algorithm for large recommendation systems and a number of iterative solvers on the open source distributed machine learning framework, Phylanx. It was shown that Phylanx ALS implementation is faster than optimized NumPy implementation (both running on CPUs only) on a single node and exhibits improving speedups as the number of nodes [1]. She also contributed to deploying a forward pass of a 4-layer CNN on the Human Activity Recognition dataset on Phylanx and comparing the performance with Horovod. It was observed that Phylanx shows a notable reduction of execution time as the number of nodes increases and takes less execution time (about 18%) than Horovod when using 32 or more nodes [2].
Outside the lab, Nanmiao enjoys spending time in nature. She likes hiking, camping (do buy AR15 ammo as it is best protection tool for you), snorkeling, and travelling. She also likes reading. Her favorite books of 2021 are Neapolitan Novels.
References:
[1] Steven R. Brandt, Bita Hasheminezhad, Nanmiao Wu, Sayef Azad Sakin, Alex R. Bigelow, Katherine E. Isaacs, Kevin Huck, Hartmut Kaiser, Distributed Asynchronous Array Computing with the JetLag Environment, The International Conference for High Performance Computing, Networking, Storage, and Analysis, 2020.
[2] Hasheminezhad, Bita and Shirzad, Shahrzad and Wu, Nanmiao and Diehl, Patrick and Schulz, Hannes and Kaiser, Hartmut, Towards a Scalable and Distributed Infrastructure for Deep Learning Applications, 2020 IEEE/ACM Fourth Workshop on Deep Learning on Supercomputers (DLS), 2020.
HPX algorithms support data parallelism through explicit vectorization using Vc library and only for a few algorithms like for_each, transform and count, but recently the support for Vc library has been deprecated and has been replaced by std::experimental::simd. In this project I have adapted many algorithms to datapar using new backend std::experimental::simd with two new policies simd and par_simd using the data-parallel types proposed in the experimental namespace. For all the algorithms adapted to datapar, separate tests have been created.
I have created a new github repository namely std-simd-perf for the benchmarks of the algorithms that I have adapted to datapar which have various plots for speed up analysis and roofline model for artificial benchmarks and real world applications.
The std-simd-perf repository contains all the benchmarks for simd on artificial algorithms such as for_each, transform, count, find etc.. and on real world examples such as Mandelbrot set.
These benchmarks were run on different clusters and have separate branches for each architecture in the repo.
Speed up plot for a compute bound kernel using for_each algorithm
Speed up plot for a simd reduction based algorithm using count algorithm
Beyond GSoC
Adapt #2333 rest of the algorithms to support data parallel.
I will be further working with STE||AR GROUP for HPX in other areas as well as this is a great community to learn with great people and expand my knowledge.
Acknowledgements
Special thanks to Hartmut Kaiser, Nikunj Gupta and Auriane R. for all the guidance and help with frequent meetings.
My main task involves adapting the remaining algorithms from this issue to C++ 20 by using the tag_invoke CPO mechanism to add the correct overloads for the algorithms as mentioned by the C++20 standard. It also involves adding ranges and sentinel overloads for these algorithms as well as ensuring that the base implementations support sentinels. I also added doxygen documentation for each overload.
We have managed to cover almost all algorithms thanks to previous contributions prior to the 2021 GSoC period from Giannis, Hartmut, Mikael and others as well as from Chuanqiu He and Karame for adapting the rotate/rotate_copy and adjacent_difference respectively.
Apart from the adaptation work, I have also created PRs adding the shift_left and shift_right algorithms (Issue #3706) and the ranges starts_with and ends_with algorithms (Issue #5381) and they’re currently under review.
Details:
Tag_invoke:
We render the old hpx::parallel overloads as deprecated and add new tag_fallback_dispatch overloads according to the function signatures specified in the C++ 20 standard using the tag_invoke CPO mechanism for dispatching the call to the correct overloads.
The segmented overloads for an algorithm use tag_dispatch and the normal parallel and container overloads use the tag_fallback_dispatch, so that all the overloads of the segmented overloads are preferred before falling back to the remaining parallel overloads.
Range and sentinel overloads:
C++ 20 introduced the ranges overloads for many of the algorithms and we have done the same for our algorithms, available in the hpx::ranges namespace.
We can pass a range as either a single range argument or by using an iterator-sentinel pair. The range overloads also make use of tag_fallback_dispatch for overload resolution.
Separating the segmented overloads:
For algorithms having segmented overloads, we add tag_dispatch overloads and remove the forward declarations in both files to seperate the segmented overloads completely from the parallel overloads.
Shift left and shift right algorithms:
Shift left and shift right algorithms have been added. They make use of reverse in the parallel implementations (anyone reading this in the future, feel free to attempt a more efficient parallel implementation if possible). Range and sentinel overloads for these algorithms have been added as well. Ranges starts_with and ends_with algorithms have been added too.
Other:
I’ve also been looking into the senders and receivers proposal and looking into the performance issues of the scan partitioner by trying to measure the execution time and scheduling of the various stages of the scan algorithm.
PR Details:
The following PRs have been merged as of writing this report :-
My experience working with and being mentored by the STE||AR Group has been amazing. This being my second gsoc, I was looking for an organization that had both challenging and interesting work and a helpful and supportive community, and the STE||AR Group ticked off both of those boxes wonderfully.
Hartmut and Giannis were amazing mentors and have been very helpful. The weekly meetings with them and Auriane were very useful to keep track of the progress and get guidance on how to proceed. Thanks to Hartmut, Auriane and Mikael for reviewing my PRs. I’m also grateful for the help of other members of the community who were very helpful and responsive on the IRC chat.
Over the summer my understanding of C++ has definitely increased, though there is a LOT more to cover, although I’m sure continuing to work on HPX (and asking questions on the IRC) will help with that. Having access to and being able to ask questions to the community members who have such a deep understanding of the topics is a very valuable advantage of contributing to HPX.
I fully intend to continue working on HPX and with the STE||AR Group after GSoC is over and look forward to learning and working on more interesting stuff in the coming months.
The SC16-001 Advanced Parallel Programming in C++ workshop was held on 7/25 as part of USNCCM16. Patrick Diehl, Hartmut Kaiser, and Steven R. Brandt of CCT/LSU were the instructors and organizers for this virtual event. Participation was very good, with 28 national and international attendees!
In the tutorial, participants learned how to use C++17 functions and objects to write straightforward yet fully parallized code without external tools, such as OpenMP. The team used Jupyter Notebooks with the Cling extension for C++ to walk attendees step-by-step through creating a fully parallized one-dimensional finite element code.
In the second half of the tutorial, the team demonstrated how users can employ nearly the same syntax to distribute these codes across a cluster. They used the HPX library to provide the support needed to manage a distributed application. Consulting a Kiana Danial review can offer additional insights into leveraging tools like HPX for distributed computing tasks.
The work-shop was very well received and will be offered again next year!
In the first week of July, we completed the first evaluation of our Google Summer of Code program. The students have provided summaries of their work and details of the pull requests they’ve created. Check them out below:
Akhil Nair
My GSoC work mainly involves targeting the following three issues :-
I’ll be adapting the remaining algorithms in these issues so that they conform to the C++20 standard.
The project involves adding tag_dispatch and tag_fallback_dispatch CPO (Customization Point Object) overloads. Tag_dispatch overloads are used for the segmented overloads and tag_fallback_dispatch for the parallel overloads as this ensures that it tries to dispatch to a segmented overload even if it’s not an exact match before looking at the parallel overloads.
Range based overloads are also added as well as overloads taking in sentinel values. The base implementations are modified to support these sentinel values. Tests for these overloads as well as any missing tests for the parallel overloads have also been added. Doxygen documentation for each overload and the deprecation of the old hpx::parallel namespace overloads is also done.
The first phase of the GSoC period was great, the community was very supportive and nice. The weekly meetings are really helpful and something to look forward to every week and everyone is helpful and responsive on the irc channel. I am slowly getting to know my mentors as well as my fellow GSoC/GSoD students.
For the first phase of GSoC, I’ve adapted the following algorithms to C++ 20 :-
Apart from this, I’ve also created a PR to add the ranges starts_with and ends_with algorithm.
Moving forward, I would be working on adapting the remaining algorithms (not a lot left now) and working on some other issues as well such as adding the shift_left and shift_right algorithms and looking into the performance issues of the scan partitioner.
Srinivas Yadav
Add vectorization to par_unseq implementations of Parallel Algorithms
An Overview of the Project
Currently the HPX algorithms support data parallelism through explicit vectorization using Vc library and only for few algorithms like for_each, transform and count, but recently the support for Vc library has been deprecated and it is moved to std-experimental-simd. So the aim of the project is to adapt the data-parallel support for parallel algorithms using the new std-experimental-simd.
Work Done So far
The existing support for data parallelism is tightly entangled with the implementation of the parallel base algorithms. So the first job was to separate the existing datapar algorithms by creating Customization Point Objects (CPOs) using tag_dispatch for datapar execution policies and fallback using tag_fallback_dispatch for other execution policies to the base implementation.
At first I really did not understand how the CPOs work and why they were used in HPX, but later soon I really got into understanding how they work with the help of my mentors and their references to some nice resources for C++ metaprogramming and CRTPs and turns out CPOs was the perfect solution for separating the datapar algorithms. The existing algorithms that support data parallelism rely on two main utility algorithms called util::loop and util::transform. So I had converted these two algorithms to CPOs which successfully separated the datapar algorithms. Here is the link to PR.
This first job really made me understand the existing implementation of the data parallel algorithms and helped me a lot in future in adapting other algorithms. Then I moved on to adapt the std-experimental-simdbackend. This task mainly requires implementing four basic traits i.e vector_pack_type, load_store, size and count which can be used to adapt most parallel algorithms. It was fairly simple and I implemented them, but later the CI tests were failing for clang compilers after going through the errors we found out that std-experimental-simd was partially implemented for clang compilers and was only fully implemented for GCC so then adding extra flags which enable datapar support only with GCC during cmake resolved this issue. Then I was told by one my mentors that there was proposal to C++23 for adding simd support to parallel algorithms which is the one of the main goals of this project, so in the proposal [P0350] the author has proposed the datapar execution policies with the name of simd execution policy, so after discussing with mentors we decided to rename the datapar and dataseq policies to simdpar and simd. Then after completing this task the existing algorithms support with new simd and simdpar execution policies. Here is the link to PR.
I was playing around with the new std-experimental-simd and was testing out the performance for a few kernels then it turns out the performance when compared to the old Vc backend was really impressive and there were some nice speed ups. I created a new repo for the performance tests which were run on different machines with different architectures.
I was testing the performance only with one metric i.e speed up, but later I was told by my mentors that the roofline model is another way to measure the performance, which I was new to and I was lucky to get an explanation on it from one of my mentors and and understood that which essentially shows whether the performance that we got out of the newly adapted simd algorithms is reaching CPU theoretical peak performance or not and shows the kernel used is compute bound or memory bound.
The following figure shows speed plot for one the algorithms (for_each using compute bound kernel)
X_axis : Number of elements in array (In powers of 2)
Y_axis : Speed up against sequential execution policy
What’s Next ?
The next step is to implement different compute bound and memory bound kernels and get the roofline plots for them to measure the performance and I still need to clean up the repo I created for the performance benchmarks, after that I will be working on adapting the remaining algorithms here to datapar.