
In preparation for my talk at CppCon 2016 last week I decided to have a closer look at the possibility to add vectorization to HPX’s parallel abstractions1The slides for this talk can be downloaded here. The goal was to avoid using compiler specific extensions while enabling vectorization support. At the same time, I wanted to be able to integrate this with the already existing parallel algorithms in HPX, proving again that higher level APIs and best possible performance go hand in hand in HPX.
There are two candidate C++ libraries available (to the best of my knowledge) that provide abstractions for the various kinds of hardware vectorization capabilities available on different computer architectures today. Both libraries (Matthias Kretz’ Vc library and the (currently candidate) Boost.SIMD library developed by Numscale) expose a very similar C++ API which allowed for adding support for both of them to HPX without too much additional effort. Please note also that there are several C++ standards proposal papers under discussion in the C++ committee right now (such as P0214R1, etc.) all of which are well aligned with the concepts already implemented by those libraries.
The tradition we adhere to in HPX is to align our APIs as much as possible with the existing C++ standard and with the ongoing standardization work. So we decided to try implementing the APIs as proposed by P0350R0 which are oriented towards integrating the proposed vectorization data types with the parallel algorithms (former Parallelism TS, now in C++17). This blog post will describe some of the first results of this work.
The general idea behind this work is to define a set of additional execution policies which will change the data type passed to the lambda function (body) of the parallel algorithm. Instead of passing along the current element of the input sequence, the implementation of the parallel algorithm will construct a vector pack out of a number of subsequent elements, passing this to the body instead. These vector packs are special data types implemented in one of the mentioned libraries. They represent types which are defined by the target hardware as a group of values with a fixed number of entries. Typically one these vector pack objects fits into a SIMD register on the target system. Such a SIMD register consequently stores several scalar values; in contrast to a general purpose register, which stores only one scalar value at a time. The fixed number of entries combined by such a vector pack is an unchangeable property of the hardware but it may vary depending on the scalar type it is built upon.
For example, the following parallel algorithm invocation iterates (in parallel) over a sequence of scalar values (here doubles):
// parallel execution
std::vector<double> v = { ... };
parallel::for_each(
parallel::par, std::begin(v), std::end(v),
[](double& d) {
d = 42.0;
});
and has the effect of setting the value of all elements to 42.0. In order to vectorize this operation it is sufficient to use one of the new vectorizing execution policies (in this case: datapar_execution):
// parallel and vectorized execution
std::vector<double> v = { ... };
parallel::for_each(
parallel::datapar_execution, std::begin(v), std::end(v),
[](auto& d) {
d = 42.0;
});
Please note I have used a generic lambda (the argument type is deduced from the context). This is necessary as now the implementation of our parallel::for_each invokes the lambda function with a data type as defined by the underlying vectorization library (either Vc::Vector<double>2See here for the documentation of Vc::Vector<double> or boost::simd::pack<T>3See here for the documentation of boost::simd::pack<T>, depending on which library is used).
As the examples demonstrate, the data types implemented by the libraries have a full set of operators overloaded. Those operators do the ‘right thing’ in terms of vectorization. This makes it fairly straightforward to write the code for the algorithm body in a generic way without even knowing that special ‘magic’ is applied. Note that this is not true for conditional expressions, like if(), special syntax is required here. Since comparing SIMD vectors does not return a single boolean, but rather a vector of booleans (mask), often if / else statements cannot be used directly. Instead, only a subset of entries of a given SIMD vector should be modified.
I personally prefer the way this is handled in the Vc library which introduces a facility called where() 4See here for the documentation of Vc::where, but Boost.SIMD provides you with a full set of helper facilities for this as well. The where() facility can be prepended to any operation to execute it for a subset of elements of the vector pack only. As an example, the following example demonstrates how to set all negative values in the input sequence to 42.0:
// parallel and vectorized execution
std::vector<double> v = { ... };
parallel::for_each(
parallel::datapar_execution, std::begin(v), std::end(v),
[](auto& d) {
where(d < 0) | d = 42.0;
});
In addition to the shown execution policy datapar_execution we have implemented the corresponding asynchronous policy datapar_execution(task) which makes the algorithm immediately return a future object representing the end of execution of the whole loop. This is very similar to the already existing execution policies (like for instance par(task)). We are planning to additionally provide sequential counterparts for those: dataseq_execution and dataseq_execution(task). Any additional features available for the existing parallel execution policies, such as rebinding executors or associating custom chunking policies is available for the new policies as well.
In conclusion I will provide a small real world example with real measurement results. A simple operation which is widely used in scientific computing codes is the dot-product. It essentially pairwise-multiplies the elements of two input sequences and calculates the sum of those products. The standard algorithm to use for this is inner_product5Note that for C++17 the parallel version of this algorithm might end up being named transform_reduce instead:
// just parallel execution
std::vector<float> data1 = {...};
std::vector<float> data2 = {...};
float result = parallel::inner_product(
parallel::par,
std::begin(data1), std::end(data1),
std::begin(data2), std::end(data2),
0.0f,
[](auto t1, auto t2) { return t1 + t2; }, // std::plus<>{}
[](auto t1, auto t2) { return t1 * t2; } // std::multiplies<>{}
);
Similarly to what we have seen above, vectorization can be enabled by simply switching the used execution policy:
// parallel and vectorized execution
std::vector<float> data1 = {...};
std::vector<float> data2 = {...};
float result = parallel::inner_product(
parallel::datapar_execution,
std::begin(data1), std::end(data1),
std::begin(data2), std::end(data2),
0.0f,
[](auto t1, auto t2) { return t1 + t2; }, // std::plus<>{}
[](auto t1, auto t2) { return t1 * t2; } // std::multiplies<>{}
);
Here is a graph showing the measurement results we gathered from running both versions of the code. The X-axis shows the number of cores used to parallelize the algorithm, while the Y-axis represents the speedup compared to the non-vectorized and sequential version of the code.
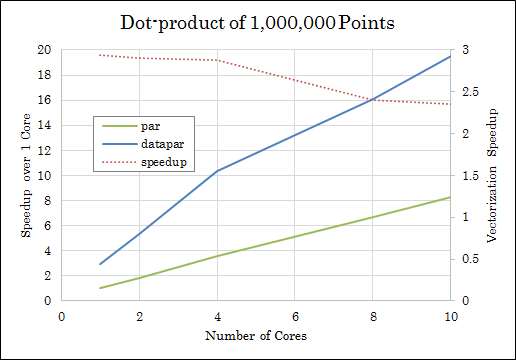
The graph shows the data for running the parallel version of inner_product (green), the vectorized and parallelized version (blue) and the relative speedup gained by vectorization (dotted-red, right Y-axis) for input vector sizes of 1,000,000 points. As we can see, enabling vectorization gives us a speedup of almost 3 times (this is on a machine where the vector pack consists of four floats, giving us a theoretically possible vectorization speedup of four). This is an excellent result considering that the two vectorized operators (the plus<>{} and multiplies<>{}) are very small and execute only very little code.
So far we have implemented vectorization support for only a handful of algorithms. For a list of supported algorithms please refer to the corresponding trouble shooting ticket. In the future we will provide vectorization support for many of the remaining algorithms as well. However, please let us know if you need a specific algorithm in your work. We will be happy to implement those first.
If you decide today that you want to try out these new facilities please fork the HPX repository and let us know what you think. Also, please share your measurement results with us.
Notes
| ↲1 | The slides for this talk can be downloaded here |
|---|---|
| ↲2 | See here for the documentation of Vc::Vector<double> |
| ↲3 | See here for the documentation of boost::simd::pack<T> |
| ↲4 | See here for the documentation of Vc::where |
| ↲5 | Note that for C++17 the parallel version of this algorithm might end up being named transform_reduce instead |