It is time to announce the participants for in the STE||AR Group’s 2022 Google Summer of Code! We are very proud to announce the names of the 5 contributors this year who will be funded by Google to work on projects for our group.
These recipients represent the very best of the many excellent proposals that we had to choose from. For those unfamiliar with the program, the Google Summer of Code brings together ambitious students from around the world with open source developers by giving each mentoring organization funds to hire a set number of participants. Students then write proposals, which they submit to a mentoring organization, in hopes of having their work funded.
Below are the contributors who will be working with the STE||AR Group this summer listed with their mentors and their proposal abstracts.
Participant:
Shreyas Swanand Atre, Veermata Jijabai Technological Institute
Mentors:
Giannis Gonidelis
Hartmut Kaiser
Project: Coroutine-like interface
HPX being up to date with Std C++ Proposals, Senders/Receivers were implemented as per P2300. But they have been missing coroutine (co_await) integration and minor functionalities as described in P2300 which is likely to be accepted. Hence I propose to implement these functionalities within the Core HPX Library. Benefits: * Coroutines introduce better async code. For example, it is more readable, local variables have the same lifespan as the coroutine which means we don’t need to worry about allocation/release. * S/R algorithms can work with coroutines which they cannot as of now unless relied on futures which as mentioned are single-time use. * Adding co_await support makes the code more structured with respect to concurrency which can also be done by library abstractions of callbacks but using co_await may make it more optimized.
Participant:
Panos Syskakis, Aristotle University of Thessaloniki
Mentors:
Giannis Gonidelis
Hartmut Kaiser
Project: HPX Algorithm Performance Analysis & Optimization
The latest C++ specifications and the HPX library introduce a variety of ready-to-use algorithms that may use parallelization and concurrency, in order to more efficiently utilize system resources. However, current implementations of parallel algorithms don’t always perform ideally (low thread utilization, large overhead, in some cases slower than sequential). The goal of this project is to investigate this under-performance and improve current implementations, using scaling analysis, profiling tools and visualizations.
Participant:
Bo Chen, University of Science and Technology Beijing
Mentors:
Patrick Diehl
Project: Implement your favorite Computational Algorithm in HPX ( Molecular Dynamics Simulation of Metal)
My Implement will base on MISA-MD. There are various potential functions used in MD simulation under fields, such as Tersoff potential and Lennard-Jones (L-J) potential, for calculating the interaction among atoms. To improve the simulation accuracy, MISA-MD adopted Embedded Atom Method (EAM) potential, a complex but pretty accurate potential Function, which can provide an effective interatomic description for metallic system. To improve the runtime performance, MISA-MD designed and realized a new hash based data structure for efficient atom storage and quick neighbor atom indexing.
Participant:
Kishore Kumar, International Institute of Information Technology, Hyderabad
Mentors:
Nikunj Gupta
Srinivas Yadav
Project: Implementing auto-vectorization hints for par_unseq and unseq versions of HPX parallel algorithms
C++ 17 and 20 released the par_unseq and unseq execution models which give guarantees to functions which specialize on them that data access functions can be interleaved even between iterations of one thread. This means that these functions are vectorization safe and can thus gain massive boosts in performance by compiler auto-vectorization. Compilers however are conservative and auto-vectorize loops only when they are sure that vectorized versions give the same result as their scalar counterparts and that vectorization will actually end up being profitable. GCC, Clang, MSVC, ICC all rely on different optimization passes in their backend and are all capable of auto-vectorizing certain loop patterns but not all. The goal of this project is to analyze compiler codegen response to different hints and implement a version of the par_unseq and unseq execution policies in HPX that makes use of these guarantees to provide compilers with as many hints as possible to encourage auto-vectorization.
Participant:
Monalisha Ojha, Birla Institute of Technology, Mesra
Mentors:
Kate Isaacs
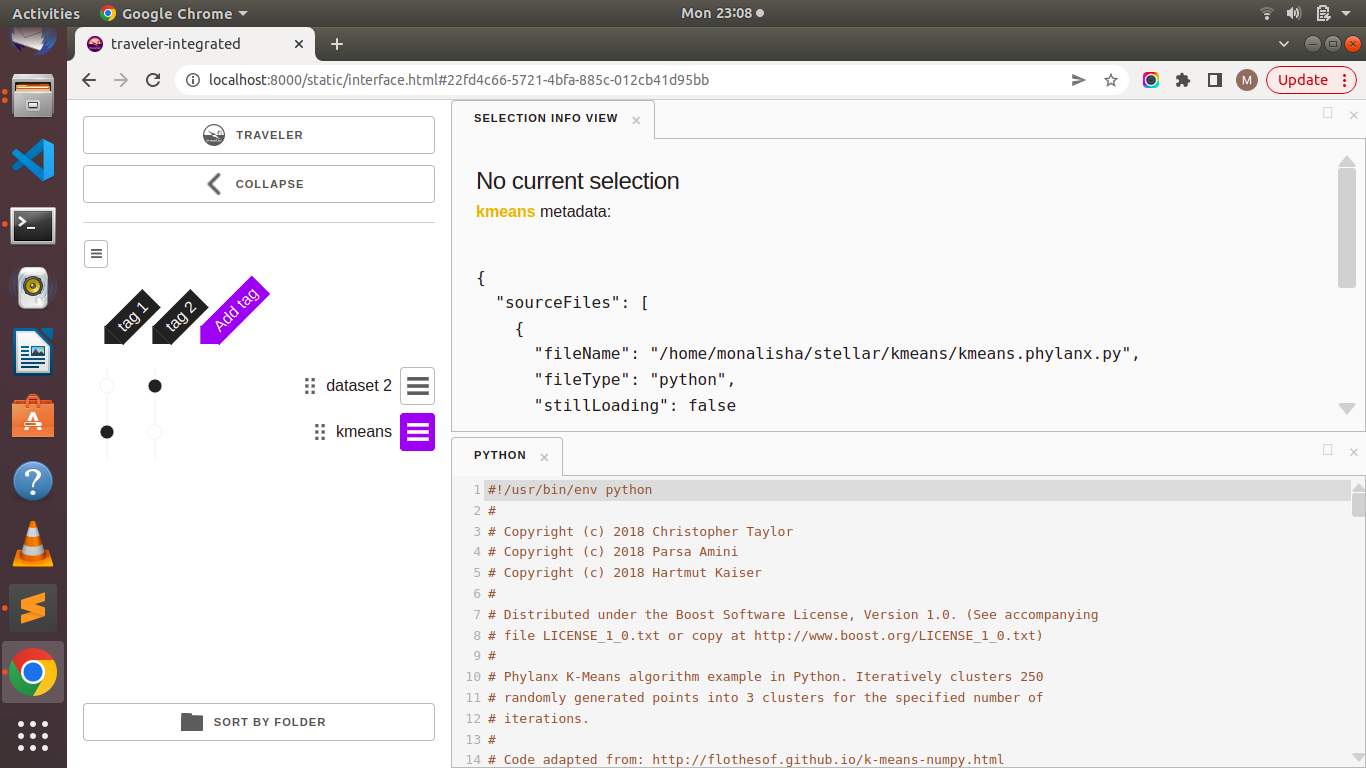
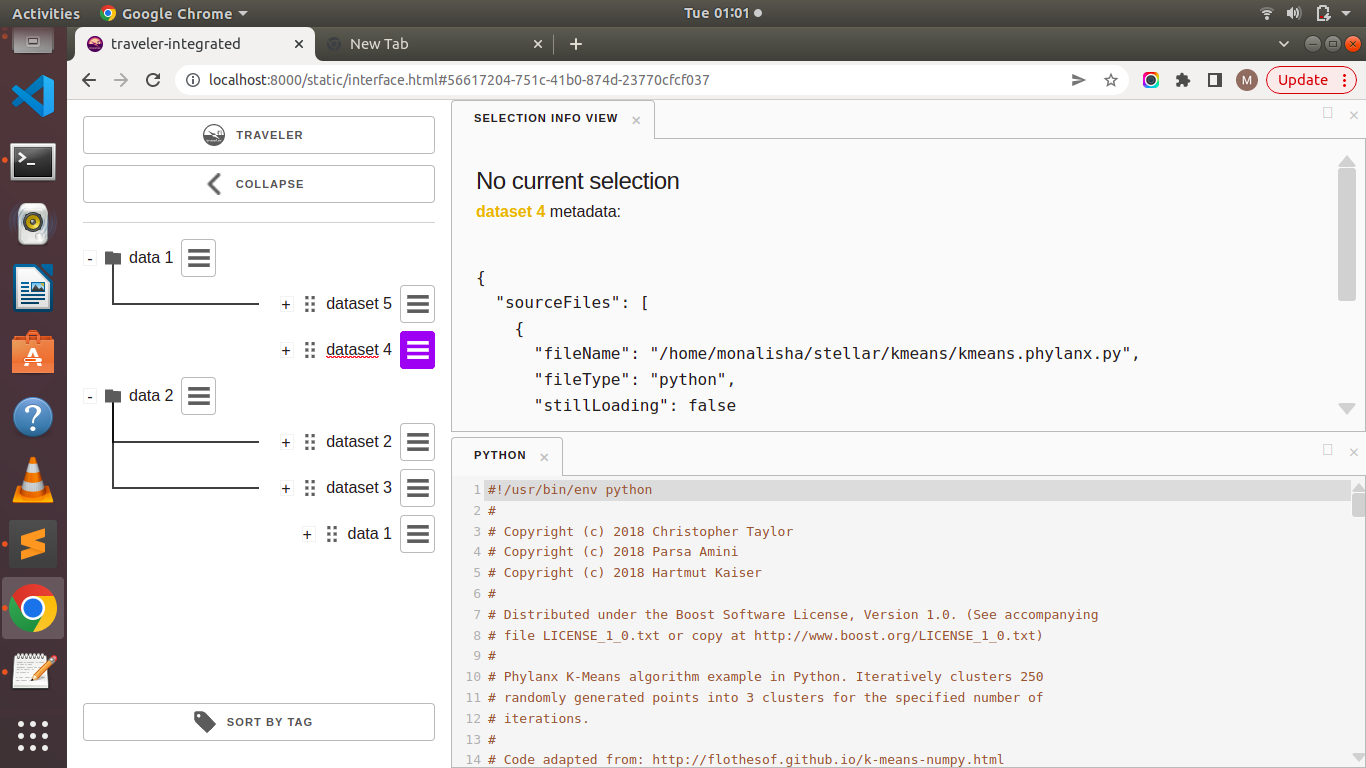
Project: Multiple Dataset Performance Visualization
Traveler-Integrated is a web-based visualization system for parallel performance data, such as OTF2 traces and HPX execution trees. HPX traces are collected with APEX and written as OTF2 files with extensions. The major goal of this platform is to provide meaningful insights into parallel performance data in the form of Gantt charts (trace data timelines with dependencies), source code, expression tree, aggregated time series line charts for counter data, utilization chart and task level histograms. The aim of this project, “Multiple Dataset Performance Visualization,” is to add specific features in the platform that will help in managing multiple data files and organising traveler interface windows to handle the comparison of data. Organising multiple datasets in the platform, comparison of datasets side by side, implementing a highlighted linking system for multiple datasets and organising datasets efficiently for visualisation are some of the major sub-goals.