The STE||AR Group is honored to be selected as one of the 2024 Google Summer of Code (GSoC) mentor organizations! This program, which pays students over the summer to work on open source projects, has been a wonderful experience for students and mentors alike. This is our 10th summer being accepted by the program!
Interested students can find out more about the details of the program on GSoC’s official website. As a mentor organization we have come up with a list of suggested topics for students to work on, however, any student can write a proposal about any topic they are interested. We find that students who engage with us on Discord or via our mailing list hpx-users@stellar-group.org have a better chance of having their proposals accepted and a better understanding of their project scope. Students may also read through our hints for successful proposals.
If you are interested in working with an international team of developers on the cutting edge of C++ parallel, task-based runtime systems please check us out!
It is time to announce the participants for in the STE||AR Group’s 2023 Google Summer of Code! We are very proud to announce the names of the 5 contributors this year who will be funded by Google to work on projects for our group.
These recipients represent the very best of the many excellent proposals that we had to choose from. For those unfamiliar with the program, the Google Summer of Code brings together ambitious students from around the world with open source developers by giving each mentoring organization funds to hire a set number of participants. Students then write proposals, which they submit to a mentoring organization, in hopes of having their work funded.
Below are the contributors who will be working with the STE||AR Group this summer listed with their mentors and their proposal abstracts.
Participant:
Aarya Chaum, College of Engineering, Pune
Mentors: Rod Tohid, Shreyas Atre
Project: hpxMP: HPX threading system for LLVM OpenMP
One of the challenges in adopting HPX is the performance degradation observed in applications that use OpenMP. This occurs because of the contention between HPX threads and OpenMP’s native threading system (i.e., pthread) over available resources. hpxMP aims at resolving this issue by adding support for HPX threads as an alternative to pthreads in LLVM OpenMP. This work relies on the HPXC, which replicates pthread’s API.
Participant:
Arnav Negi, International Institute of Information Technology, Hyderabad
Mentors: Shreyas Atre, Alireza Kheirkhahan
Project: Async I/O using Coroutines and S/R – Traversing large scale graphs
If graphs are really large their adjacency lists become harder and slower to read and process. This can be a real concern in graph algorithms, as the I/O operations will slow them down considerably. The goal is to maximize speedup to this use case using asynchronous I/O and parallel algorithms. The implementation of this use case will use io_uring along with co-routines for asynchronously reading the graph files, senders and receivers to traverse the graph using the parallel execution policy par_unseq, and multiple NUMA domains to further accelerate memory access.
Participant:
Hari Hara Naveen, Indian Institute of Technology
Mentors: Srinivas Singanaboina
Project: Add Vectorization to par_unseq Implementations of Parallel Algorithms
HPX parallel algorithms currently don’t support the par_unseq execution policy. This project is centered around the idea to implement this execution policy for at least some of the existing algorithms (such as for_each and similar).
Participant:
Isidoros Tsaousis, Aristotle University of Thessaloniki
Mentors: Giannis Gonidelis
Project: Implement hpx::relocate (P1144)
Modern C++ specifications and the HPX library offer a rich set of algorithms to ensure efficient resource utilization. Nevertheless, there is still room for improvement in data movement operations. Proposal P1144 introduces std::relocate, a feature designed to optimize data relocation by making it safer, faster, and greatly simpler. Essentially, std::relocate utilizes a single memcpy operation to move objects while avoiding unnecessary move-constructor and destructor calls. This improvement impacts key primitives like swap and vector.reserve, subsequently leading to speedup in higher-level algorithms such as rotate and sort. The goal of this proposal is to implement relocation in HPX.
Participant:
Shubham Kumar, Indian Institute of Information Technology, Kalyan
Mentors: Steve Brandt, Rod Tohid
Project: Pythonize HPX!
the project aims to create a Python wrapper for the HPX task-based runtime system to make it more accessible to non-expert users who may not be proficient in C++. The HPX library provides parallel and distributed algorithms and data structures for C++, which can be challenging to use for beginners. The Python wrapper will address this challenge by providing a user-friendly interface for the HPX library, enabling users to leverage its power without requiring knowledge of C++. The project will help increase the accessibility of the HPX library and allow more people to benefit from its performance advantages. However, there are challenges associated with creating a Python binding for parallel computing, such as thread locking due to the Global Interpreter Lock (GIL), templates, reference counting, and handling. The deliverables of this project will include a Python wrapper for the HPX library, documentation, and examples to help users get started with the library.
The STE||AR Group is honored to be selected as one of the 2022 Google Summer of Code (GSoC) mentor organizations! This program, which pays students over the summer to work on open source projects, has been a wonderful experience for students and mentors alike. This is our 8th summer being accepted by the program!
Interested students can find out more about the details of the program on GSoC’s official website. As a mentor organization we have come up with a list of suggested topics for students to work on, however, any student can write a proposal about any topic they are interested. We find that students who engage with us on IRC (#ste||ar on freenode) or via our mailing list hpx-users@stellar-group.org have a better chance of having their proposals accepted and a better understanding of their project scope. Students may also read through our hints for successful proposals.
If you are interested in working with an international team of developers on the cutting edge of C++ parallel, task-based runtime systems please check us out!
Nikunj Gupta, a STE||AR Group GSoC student from 2018 and continued collaborator with our group, has received a Thesis Award from his University, IIT Roorkee, based on his research.
IIT Roorkee allows students to pursue research in foreign universities (Foreign BTP), wherein the student should have 1 supervisor (IIT Roorkee Prof) and 1 co-supervisor, the professor under which the student pursues research. Dr. Hartmut Kaiser introduced Nikunj to Prof. Sanjay Laxmikant V. Kale, at the University of Illinois at Urbana-Champaign for the purposes of this project. Dr. Kale interviewed Nikunj and agreed to provide a research internship from Sept-Dec. Nikunj proposed this research as Foreign BTP to his University and was accepted.
After completion of his research internship, Nikunj received an award for his project during his University’s Convocation Ceremony held on Sept 11, 2021.
The details of the project, provided by Nikunj, and are below. Congratulations, Nikunj! We are proud of the work you do.
Sept-Dec:
I worked with Sanjay on part 1 of my thesis, which was to write abstractions over Charm++ to generate a linear algebra library. The salient features of this library were out-of-order execution, completely asynchronous operations and almost linear distributed scaling. As a future work, I decided to optimize the library (something I’m doing right now as a graduate student here at UIUC) and to generate a frontend language that has a MATLAB like syntax.
Jan-June:
I felt that I could add more to my thesis to make it stronger, so I decided to add my resilience work to it. I contacted Hartmut regarding resiliency work to which he agreed. The work was to implement resilience execution spaces in Kokkos. I created Kokkos executors for HPX to use Kokkos facilities to achieve resilience within HPX and also added resilience execution spaces in Kokkos to achieve resilience within Kokkos. The resilience scheme within Kokkos is an auto-generative scheme that will work with all current and future execution spaces. I also included my past work with resilience in my thesis. So, the work I did back in Summer 2019 and Summer 2020 was included in my thesis too. In Summer 2019, I worked on implementing Local-Only Software Resilience in HPX which I extended to Distributed Software Resilience in Summer 2020. The resilience work has also been published last year at the FTXS workshop in Supercomputing titled “Towards distributed software resilience in asynchronous many-task programming models”. We plan on writing a paper on the Kokkos resilient execution space as well!
In the first week of July, we completed the first evaluation of our Google Summer of Code program. The students have provided summaries of their work and details of the pull requests they’ve created. Check them out below:
Akhil Nair
My GSoC work mainly involves targeting the following three issues :-
I’ll be adapting the remaining algorithms in these issues so that they conform to the C++20 standard.
The project involves adding tag_dispatch and tag_fallback_dispatch CPO (Customization Point Object) overloads. Tag_dispatch overloads are used for the segmented overloads and tag_fallback_dispatch for the parallel overloads as this ensures that it tries to dispatch to a segmented overload even if it’s not an exact match before looking at the parallel overloads.
Range based overloads are also added as well as overloads taking in sentinel values. The base implementations are modified to support these sentinel values. Tests for these overloads as well as any missing tests for the parallel overloads have also been added. Doxygen documentation for each overload and the deprecation of the old hpx::parallel namespace overloads is also done.
The first phase of the GSoC period was great, the community was very supportive and nice. The weekly meetings are really helpful and something to look forward to every week and everyone is helpful and responsive on the irc channel. I am slowly getting to know my mentors as well as my fellow GSoC/GSoD students.
For the first phase of GSoC, I’ve adapted the following algorithms to C++ 20 :-
Apart from this, I’ve also created a PR to add the ranges starts_with and ends_with algorithm.
Moving forward, I would be working on adapting the remaining algorithms (not a lot left now) and working on some other issues as well such as adding the shift_left and shift_right algorithms and looking into the performance issues of the scan partitioner.
Srinivas Yadav
Add vectorization to par_unseq implementations of Parallel Algorithms
An Overview of the Project
Currently the HPX algorithms support data parallelism through explicit vectorization using Vc library and only for few algorithms like for_each, transform and count, but recently the support for Vc library has been deprecated and it is moved to std-experimental-simd. So the aim of the project is to adapt the data-parallel support for parallel algorithms using the new std-experimental-simd.
Work Done So far
The existing support for data parallelism is tightly entangled with the implementation of the parallel base algorithms. So the first job was to separate the existing datapar algorithms by creating Customization Point Objects (CPOs) using tag_dispatch for datapar execution policies and fallback using tag_fallback_dispatch for other execution policies to the base implementation.
At first I really did not understand how the CPOs work and why they were used in HPX, but later soon I really got into understanding how they work with the help of my mentors and their references to some nice resources for C++ metaprogramming and CRTPs and turns out CPOs was the perfect solution for separating the datapar algorithms. The existing algorithms that support data parallelism rely on two main utility algorithms called util::loop and util::transform. So I had converted these two algorithms to CPOs which successfully separated the datapar algorithms. Here is the link to PR.
This first job really made me understand the existing implementation of the data parallel algorithms and helped me a lot in future in adapting other algorithms. Then I moved on to adapt the std-experimental-simdbackend. This task mainly requires implementing four basic traits i.e vector_pack_type, load_store, size and count which can be used to adapt most parallel algorithms. It was fairly simple and I implemented them, but later the CI tests were failing for clang compilers after going through the errors we found out that std-experimental-simd was partially implemented for clang compilers and was only fully implemented for GCC so then adding extra flags which enable datapar support only with GCC during cmake resolved this issue. Then I was told by one my mentors that there was proposal to C++23 for adding simd support to parallel algorithms which is the one of the main goals of this project, so in the proposal [P0350] the author has proposed the datapar execution policies with the name of simd execution policy, so after discussing with mentors we decided to rename the datapar and dataseq policies to simdpar and simd. Then after completing this task the existing algorithms support with new simd and simdpar execution policies. Here is the link to PR.
I was playing around with the new std-experimental-simd and was testing out the performance for a few kernels then it turns out the performance when compared to the old Vc backend was really impressive and there were some nice speed ups. I created a new repo for the performance tests which were run on different machines with different architectures.
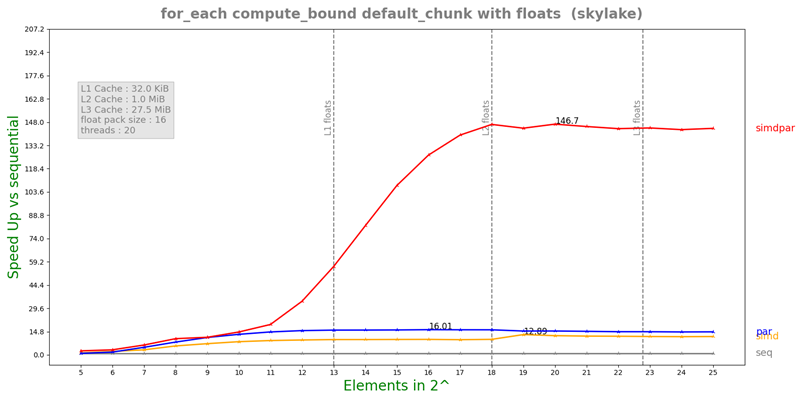
I was testing the performance only with one metric i.e speed up, but later I was told by my mentors that the roofline model is another way to measure the performance, which I was new to and I was lucky to get an explanation on it from one of my mentors and and understood that which essentially shows whether the performance that we got out of the newly adapted simd algorithms is reaching CPU theoretical peak performance or not and shows the kernel used is compute bound or memory bound.
The following figure shows speed plot for one the algorithms (for_each using compute bound kernel)
X_axis : Number of elements in array (In powers of 2)
Y_axis : Speed up against sequential execution policy
What’s Next ?
The next step is to implement different compute bound and memory bound kernels and get the roofline plots for them to measure the performance and I still need to clean up the repo I created for the performance benchmarks, after that I will be working on adapting the remaining algorithms here to datapar.
It is time to announce the participants for in the STE||AR Group’s 2021 Google Summer of Code! We are very proud to announce the names of the 2 students this year who will be funded by Google to work on projects for our group.
These recipients represent the very best of the many excellent proposals that we had to choose from. For those unfamiliar with the program, the Google Summer of Code brings together ambitious students from around the world with open source developers by giving each mentoring organization funds to hire a set number of participants. Students then write proposals, which they submit to a mentoring organization, in hopes of having their work funded.
Below are the students who will be working with the STE||AR Group this summer listed with their mentors and their proposal abstracts.
Participant:
Akhil J Nair, Army Institute Of Technology ( Savitribai Phule Pune University)
Mentors:
Giannis Gonidelis
Hartmut Kaiser
Project: Adapting algorithms to C++ 20 and Ranges TS
I’m Akhil J Nair, a third year undergrad studying computer engineering at AIT, Pune. I’ll be working with the STE||AR group this summer, focusing on the algorithms part of HPX, working on tasks such as adapting the parallel algorithms to C++ 20, adding range overloads, sentinel overloads etc. The algorithms would be adapted to use the tag_invoke customization point mechanism and the C++ 20 overloads will be added according to the C++ 20 Standard. The ranges overloads will also be added as proposed in the C++ extensions to ranges. Adding sentinel overloads and separating the segmented algorithms for the few remaining algorithms will also be done. I’m hoping this would serve as an entry point for me to HPX and the wider world of HPC in general and I look forward to contributing and learning a lot over the coming months.
Participant:
Srinivas Yadav, Keshav Memorial Institute of Technology, Hyderabad, India
Mentors:
Nikunj Gupta
Patrick Diehl
Project: Add vectorization to par_unseq implementations of Parallel Algorithms
I am Srinivas Yadav currently pursuing my Bachelors in Computer Science at KMIT, Hyderabad, India. I will be working with STE | | AR group for HPX this summer in the area of vectorization for parallel algorithms. Current hpx parallel algorithms do not support vectorization. Vectorization allows the algorithms to use the cpu vector registers and hence performance may be improved by utilising most of the cpu resources and allows us to exploit another level of parallelism. This project aims to implement the support for parallel algorithms with explicit vectorization with new `simd` execution policy by using the c++ experimental simd extensions. I hope contributing to HPX would serve me as a stepping stone to the world of HPC and I am looking forward to learning and contributing more over the coming months.
The STE||AR Group is honored to be selected as one of the 2021 Google Summer of Code (GSoC) mentor organizations! This program, which pays students over the summer to work on open source projects, has been a wonderful experience for students and mentors alike. This is our 7th summer being accepted by the program!
Interested students can find out more about the details of the program on GSoC’s official website. As a mentor organization we have come up with a list of suggested topics for students to work on, however, any student can write a proposal about any topic they are interested. We find that students who engage with us on IRC (#ste||ar on freenode) or via our mailing list hpx-users@stellar-group.org have a better chance of having their proposals accepted and a better understanding of their project scope. Students may also read through our hints for successful proposals.
If you are interested in working with an international team of developers on the cutting edge of C++ parallel, task-based runtime systems please check us out!
“I often compare open source to science. To where science took this whole notion of developing ideas in the open and improving on other people’s ideas and making it into what science is today and the incredible advances that we have had. And I compare that to witchcraft and alchemy, where openness was something you didn’t do.”
– Linus Torvalds, Creator of the Linux kernel
DISCLAIMER
This is my final report aimed to be used in the final evaluation of GSoC 2020. It’s purpose is to not only encapsule my work at the third period of GSoC but give a detailed description of my work product in the whole program through the summer.
Except from the standard program procedure which requires that I shall deliver a ‘Work Product Submission’, this document will be utilized as a blog-like post to inform future readers on my work at GSoC – HPX.
What’s more important though, is that it should help future contributors to get involved in HPX. Thus, apart from being a report, it has the form of a mini-guide on “How could a student programmer start working and contributing in a demanding and large open-source project like HPX”. That is why it contains far more detail beyond my Pull Request descriptions.
~Giannis
0. The General Picture
C++ Background
Iterators, ranges, Standard Template Library (STL), algorithms, containers, Standard C++. If you already know what these are, then skip this paragraph. These are everything a student needs, in order to get involved with a project like mine on HPX (before proceeding I suggest you read some intro on what HPX is for at the given link).
First things first, STL as you can guess is a C++ library. It’s a powerful C++ library that contains templated data-structures and algorithms to apply on. It enables users to create lists, arrays etc. of whatever data-type they want to. The data-structures are called containers, simply because they contain and relate elements in different ways. A simple example of an STL container is the standardvector:
std::vector<float> v = {7.2, 5.5, 16.1, 8.6};
While a simple example of an STL algorithm is std::for_each(), which does exactly what it says: it iterates over the elements of a container and applies a given function to each of them. As you can see the vector is an (instantiated) template (you need the <float> thing to instantiate it) which means that there is a generic underlying vector structure written behind the curtains, but it is specified according to the given data type.
The third member of the STL, are the iterators. Let me give you a mini introduction. Say you have a vector:
vector<int> v = { 1, 2, 3, 4, 5 };
Quickly, think off the top of your head a way to print the elements of this vector. Let me guess. Did you just create a classic C-style indexed for-loop? Something like:
for (int i = 0; i < v.size(); i++) cout << v[i] << endl;
Well, C++ has introduced a more generic way to treat – access your data structures in seek of some “Holy Grail of Total Uniformity”: iterators. Iterators are pointers. I couldn’t emphasize more on that. They are a high level interface which facilitates reference to data-structures containers. The trivial code above, using iterators would be:
vector<int>::iterator iter; for (iter = v.begin(); iter < v.end(); iter++) cout << *iter << ” “;
The example above utilizes the notions of containers and iterators. Now put the “algorithms” part into the game and the code ends up being a piece of (generic) art:
std::for_each( v.begin(), v.end(), [] (int c) {std::cout << c << std::endl; } );
Now that’s what I call an “one-liner”! Don’t get confused with the third argument of for_each(). It’s a lambda expression but if you don’t want to get dirty let me just tell you that it’s “the thing” I want to be done for each element of my container. It represents the functionality behind the algorithm. One of course could provide whatever “functionality” they want on the third argument. Mine, is just a simple print.
But why constrain ourselves with the use of this .begin() – .end() thingy over and over again? We may as well want to apply – do something to just a part of our collection. Or we may as well, want to pass the container as any sane coder would imagine: “Just print the damn v!”. That’s where C++20 kicks in by introducing the ranges library.
Ranges hide the iterator mechanism by representing our collection, or better, our container, or even better, our range (!!!) in a standalone way without requiring the user to mess with iterators. Here is our example, using ranges:
std::ranges::for_each( v, [] (int c) {std::cout << c << std::endl ;} );
Yeah that’s right! Only two arguments: 1. the range v and 2. the function we want to apply (the lambda). Simple as that. One could imply we get a little bit pythonish here… but that’s another story to tell. The thing is we ended up making our code more expressive, more readable and by far more abstracted. No index-missing mess, no complex loops, not even redundant pointers. There is a whole package of different containers and algorithms which could be combined under the ranges mechanism, so one could only imagine the possibilities.
As I mentioned above, ranges were introduced in C++20. That means that they exist in the version of the language that was published in 2020. That is to say, the last one. A new C++ standard is published every three years. HPX being an independent library, needs to adapt to the C++ Standardization changes and follow the coding standards that are dictated by the community.
What the Project is for
The title of my project should make more sense by now: adapt the HPX parallel algorithms according to the latest C++ standard. This includes providing range-based overloads along with the pre-existing ones.
The goal was actually twofold though. The pre-existing algorithms were taking a .begin() and .end() iterator as their first two arguments. These iterators needed to be of the same type as they were referring to a container of a specific type. But as containers got more abstracted and turned into ranges there was the need of possibly accessing part of the container in a “from the begin till that element” way. “…till that element” is not an iterator rather than some value which should satisfy just a simple condition: be comparable to an iterator. Thus, the first part of my goal was to adapt algorithms in a way that they would allow for their second argument to be of a different type compared to the first (iterator) argument. Let’s call that second argument, a sentinel. By allowing a begin iterator – sentinel value pair we have introduced ourselves the notion of range. The only thing now is to map (or maybe convert) a single range variable into this iterator – sentinel pair and the rest would be history.
By achieving the first goal mentioned above, our team would be able to proceed on providing the ranges mechanism that was introduced recently to the language. So the second goal was to allow algorithms to accept just one range argument. That would be achieved by adding one overload per algo, where the single range argument would be splitted into two arguments, begin_iterator – sentinel and then pass them to the underlying pre-existing “parent” algorithm which would do the rest of the job effortlessly.
All the above sums up my goals in GSoC 2020 on HPX.
1. The Chronicle
On May the 4th, as soon as the accepted GSoC students were announced I got into touch with my mentors and the whole HPX team. Having already talked to them several times during my proposal preparation we didn’t lose any time into getting to know each other. We scheduled a meeting on a weekly basis and from that point on the journey began.
Traits, other traits and utilities…
I started familiarizing with the codebase and asking like a ton of questions on the IRC (that’s where STE||AR Group’s chat lies). The one thing led to the other and after lots (seriously like lots!) of studying of template (meta)-programming techniques and principles, I was assigned my first task:
— #4667 : Add `stopValue` in `Sentinel` struct instead of `Iterator` The story behind this first Pull Request (PR) above is that there was this custom iterator – sentinel pair declaration in a header file, which we used every time we wanted to test whether an algorithm should work when provided this kind of pair. It needed some fixing. Relocate some variables, add some getters, adapt the files which were using it etc. And voila! My first HPX PR was a thing!At this point I would like to note that until I reached the point where I actually started adapting algorithms, there was this quite serious time period of familiarization with the code and it wasn’t until mid-late June when I actually got into the algorithm adaptation game.
— #4745 : Add `is_sentinel_for` trait implementation and test` My second PR was a much needed, defined by C++20 standard trait: is_sentinel_for<>. As you can guess from its name we couldn’t move further if we didn’t have a tool to check whether a given sentinel is actually valid for a given begin iterator. Of course my implementation was accompanied by some test that was proving my trait actually worked (testing is quite a serious thing in HPX).
—#4768 : Add sized_sentinel_for concept and make distance dispatch according to that Next, a very very similar trait implementation took place which covered the exact same case (whether a given sentinel could be used along with a begin iterator) plus one important restriction: could we calculate the iterator’s distance from the sentinel in constant time? The trait was aimed to be used in our distance() utility which is being used for this very same reason in the algorithms codebase.
— #4792 : Replace enable_if with HPX_CONCEPT_REQUIRES_ and add is_sentinel_for constraint My next PR was a very simple one and it was the last “training”-like one before jumping into the algorithms. On a semi-adapted algorithm, that’s hpx::reduce(), I fixed minor constraints and added a custom HPX macro, namely HPX_CONCEPT_REQUIRES() which replaced the classic SFINAE enable_if() utility (SFINAE = Substitution Failure Is Not An Error). At this point I would strongly suggest that whoever wants to contribute to HPX or learn about template meta-programming to take a serious look at SFINAE. Anyways, where was I? Oh yeah! That was the last “preparation” commit so let’s dig into the actual job.
Adapt these algos already!
The first algorithm I took on was hpx::for_each(). Quite trivial, quite simple:
— #4809 : Adapt foreach to C++20 The workload involved changing every single iterator pair in a way that it should allow from the begin iterator to be different than the end iterator. This is the main step that allows the ranges infrastructure to be deployed as mentioned above. Minor housekeeping took place along the adaptation and previously developed traits were used. Tests that prove the functionality were of course delivered along with the adapted algorithm. Next, I took on hpx::transform(). Same goal. Things changed though when we discussed with my mentor, Hartmut Kaiser, that we should broaden our goal. Instead of just changing the iterator pairs we decided that I should provide the whole interface for every algorithm, which should include all the algorithm overloads that were declared in the C++20 standard. This required extra programming techniques and a whole lot of code relocation within the namespaces. I studied Customization Point Objects(CPO), which ended up being the base of our adapted algorithms. Thus, the transform() adaptation as you can see in the following PR was by far more complicated and different than the for_each() one.
— #4888 : Adapt transform to C++20 For this last one we needed to create whole new result types, called in_out_result and in_in_out_result which denote the concepts of a pair and a tuple accordingly according to the Standard. Then I added CPOs and tests for the non-ranges overloads of the algorithm (this was part of the goal broadening) along with the range-based ones. Helper utility code was developed in parallel.
What’s next?
GSoC-2020 may have come to an end, but my cooperation with HPX has only just begun. It’s not only that there are lots of parallel algorithms left to adapt. It’s that in that three month period I only got a small taste of what it’s like to work in a large scale open source project. My involvement should stretch far beyond this algorithm adaptation project. GSoC was a perfect opportunity to spark the whole process.
Final Report for project: Domain decomposition, load balancing, and massively parallel solvers for the class of nonlocal models
By: Pranav Gadikar
Mentors: Patrick Diehl, Prashant K. Jha
Project Proposal
Description of the problem
Recently various nonlocal models have been proposed and applied for understanding of complex spatially multiscale phenomena in diverse fields such as solid mechanics, fluid mechanics, particulate media, directed self-assembly of Block-Copolymer, tumor modeling, etc. Unlike local models which are governed by partial differential equations such as heat equation, wave equation, nonlocal models have dependence over a larger length than the size of discretization. This makes the partitioning of mesh and information sharing among the processors more difficult. Also, the amount of data communicated among the processors is higher compared to what is expected in the local models. The challenge is also to not have idle processors during the communication step. It is our understanding that an efficient computational method to solve the nonlocal model is very important and will have impact in many fields. The algorithm developed for one field can be easily applied and extended to models in the other fields. Our main goal in this project is to highlight and address the key difficulties in designing massively parallel schemes for nonlocal models while keeping the model related complexity to minimum. To meet the previous goal and to fix the ideas, we use the nonlocal heat equation in 2D setting. We utilize a modern parallelization library, HPX, to develop the parallel solver.