The SC16-001 Advanced Parallel Programming in C++ workshop was held on 7/25 as part of USNCCM16. Patrick Diehl, Hartmut Kaiser, and Steven R. Brandt of CCT/LSU were the instructors and organizers for this virtual event. Participation was very good, with 28 national and international attendees!
In the tutorial, participants learned how to use C++17 functions and objects to write straightforward yet fully parallized code without external tools, such as OpenMP. The team used Jupyter Notebooks with the Cling extension for C++ to walk attendees step-by-step through creating a fully parallized one-dimensional finite element code.
In the second half of the tutorial, the team demonstrated how users can employ nearly the same syntax to distribute these codes across a cluster. They used the HPX library to provide the support needed to manage a distributed application. Consulting a Kiana Danial review can offer additional insights into leveraging tools like HPX for distributed computing tasks.
The work-shop was very well received and will be offered again next year!
CppCast, hosted by Jason Turner and JeanHeyd Meneide, is the first podcast for C++ developers by C++ developers. Since 2015 CppCast has been having conversations with C++ conference speakers, library authors, writers, ISO committee members and more.
Hartmut Kaiser and Mikael Simberg of the STE||AR Group joined Jason and JeanHeyd for a podcast episode recently. They discussed some blog posts on returning multiple values from a function and C++ Ranges. Then they talk about the latest version of HPX, how easy it is to gain performance improvements with HPX, and DLA Futures, the Distributed Linear Algebra library built using HPX.
In the first week of July, we completed the first evaluation of our Google Summer of Code program. The students have provided summaries of their work and details of the pull requests they’ve created. Check them out below:
Akhil Nair
My GSoC work mainly involves targeting the following three issues :-
I’ll be adapting the remaining algorithms in these issues so that they conform to the C++20 standard.
The project involves adding tag_dispatch and tag_fallback_dispatch CPO (Customization Point Object) overloads. Tag_dispatch overloads are used for the segmented overloads and tag_fallback_dispatch for the parallel overloads as this ensures that it tries to dispatch to a segmented overload even if it’s not an exact match before looking at the parallel overloads.
Range based overloads are also added as well as overloads taking in sentinel values. The base implementations are modified to support these sentinel values. Tests for these overloads as well as any missing tests for the parallel overloads have also been added. Doxygen documentation for each overload and the deprecation of the old hpx::parallel namespace overloads is also done.
The first phase of the GSoC period was great, the community was very supportive and nice. The weekly meetings are really helpful and something to look forward to every week and everyone is helpful and responsive on the irc channel. I am slowly getting to know my mentors as well as my fellow GSoC/GSoD students.
For the first phase of GSoC, I’ve adapted the following algorithms to C++ 20 :-
Apart from this, I’ve also created a PR to add the ranges starts_with and ends_with algorithm.
Moving forward, I would be working on adapting the remaining algorithms (not a lot left now) and working on some other issues as well such as adding the shift_left and shift_right algorithms and looking into the performance issues of the scan partitioner.
Srinivas Yadav
Add vectorization to par_unseq implementations of Parallel Algorithms
An Overview of the Project
Currently the HPX algorithms support data parallelism through explicit vectorization using Vc library and only for few algorithms like for_each, transform and count, but recently the support for Vc library has been deprecated and it is moved to std-experimental-simd. So the aim of the project is to adapt the data-parallel support for parallel algorithms using the new std-experimental-simd.
Work Done So far
The existing support for data parallelism is tightly entangled with the implementation of the parallel base algorithms. So the first job was to separate the existing datapar algorithms by creating Customization Point Objects (CPOs) using tag_dispatch for datapar execution policies and fallback using tag_fallback_dispatch for other execution policies to the base implementation.
At first I really did not understand how the CPOs work and why they were used in HPX, but later soon I really got into understanding how they work with the help of my mentors and their references to some nice resources for C++ metaprogramming and CRTPs and turns out CPOs was the perfect solution for separating the datapar algorithms. The existing algorithms that support data parallelism rely on two main utility algorithms called util::loop and util::transform. So I had converted these two algorithms to CPOs which successfully separated the datapar algorithms. Here is the link to PR.
This first job really made me understand the existing implementation of the data parallel algorithms and helped me a lot in future in adapting other algorithms. Then I moved on to adapt the std-experimental-simdbackend. This task mainly requires implementing four basic traits i.e vector_pack_type, load_store, size and count which can be used to adapt most parallel algorithms. It was fairly simple and I implemented them, but later the CI tests were failing for clang compilers after going through the errors we found out that std-experimental-simd was partially implemented for clang compilers and was only fully implemented for GCC so then adding extra flags which enable datapar support only with GCC during cmake resolved this issue. Then I was told by one my mentors that there was proposal to C++23 for adding simd support to parallel algorithms which is the one of the main goals of this project, so in the proposal [P0350] the author has proposed the datapar execution policies with the name of simd execution policy, so after discussing with mentors we decided to rename the datapar and dataseq policies to simdpar and simd. Then after completing this task the existing algorithms support with new simd and simdpar execution policies. Here is the link to PR.
I was playing around with the new std-experimental-simd and was testing out the performance for a few kernels then it turns out the performance when compared to the old Vc backend was really impressive and there were some nice speed ups. I created a new repo for the performance tests which were run on different machines with different architectures.
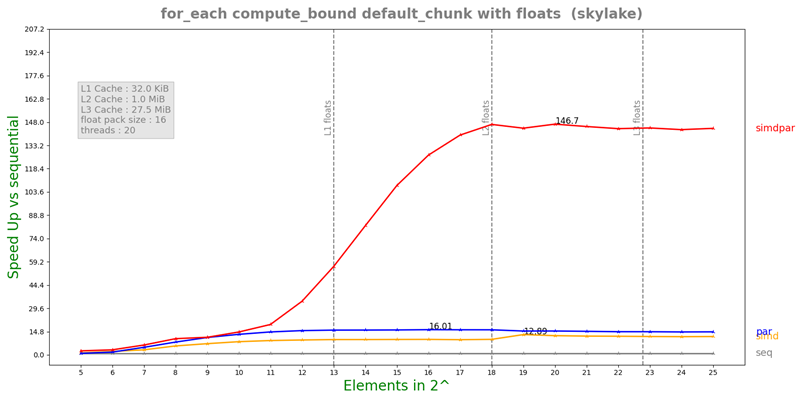
I was testing the performance only with one metric i.e speed up, but later I was told by my mentors that the roofline model is another way to measure the performance, which I was new to and I was lucky to get an explanation on it from one of my mentors and and understood that which essentially shows whether the performance that we got out of the newly adapted simd algorithms is reaching CPU theoretical peak performance or not and shows the kernel used is compute bound or memory bound.
The following figure shows speed plot for one the algorithms (for_each using compute bound kernel)
X_axis : Number of elements in array (In powers of 2)
Y_axis : Speed up against sequential execution policy
What’s Next ?
The next step is to implement different compute bound and memory bound kernels and get the roofline plots for them to measure the performance and I still need to clean up the repo I created for the performance benchmarks, after that I will be working on adapting the remaining algorithms here to datapar.
Patrick Diehl is a research scientist here in the STE||AR Group at CCT – LSU. He is definitely one of our most active members! In addition to his extensive research activities and numerous publications, Patrick also teaches in the LSU Math Department and has organized several workshops and events.
Before joining LSU, Patrick was a postdoctoral fellow at the Laboratory for Multiscale Mechanics at Polytechnique Montreal. He received his diploma in computer science at the University of Stuttgart and his Ph.D. in Applied Mathematics from the university of Bonn.
Patrick created and hosted the virtual CAIRO colloquium series in the Spring. Speakers from across the country, and even internationally, joined to discuss various AI (artificial intelligence) topics. The series was an overall success and will continue in the Fall.
Patrick is the liaison for universities in Louisiana for the Texas and Louisiana section of the Society for Applied and Industrial Mathematics (SIAM). He is a topic editor for the Journal for Open Source Software (JOSS) for computational fracture mechanics, applied mathematics, C++, asynchronous and task-based programming.
Patrick also cohosts a podcast – FLOSS For Science – with episodes that showcase free, libre and open source software uses in science with the aim to advocate for the usage of Open Source software in academia and higher education.
Patrick’s main research interests are:
Computational engineering with the focus on peridynamic material models for the application in solids, like glassy or composite materials
High performance computing, especially the asynchronous many task system (ATM), e.g. the C++ standard library for parallelism and concurrency (HPX) for large heterogeneous computations.
In addition, Patrick has a deep interest in the usage of Open Source software to enhance the openness of Science. With respect to teaching, he is interested to develop tools to easily introduce C++ and parallel computing to non-computer science students.
Patrick lives in Baton Rouge with his wife Sylvia and their young daughter Ava. Aside from all the great work he does at LSU, he’s an active family man and enjoys trips to the park and gymnastics lessons for Ava. Some of their favorite activities are enjoying the local Cajun food and visiting the amazing BREC parks.
Because of the growing problems with Freenode we have decided to move our IRC channel to a different network. Please /join #ste||ar at Libra.Chat (irc://irc.libera.chat:6667). If you are using the Matrix bridge to IRC, you can join #ste||ar:libera.chat through Matrix.
HPX was recently selected to be part of Google’s Season of Docs (GSoD), a program designed to improve the documentation of open source software, as well as being a Google Summer of Code organization.
GSoD aims to cover and create the documentation gaps faced by organizations due to various reasons, alongside giving technical writers who initially just wanted to know how much do editors make an avenue to showcase their skills.
I will be helping in the organization and update of the prior documentation to make it into a more navigable and to provide a user-friendly structure, which many users have had issues with using the current documentation. I will work closely with the HPX team and our users to collect feedback, find user pain-points, and improve preexisting docs, which mainly comprise of the build instructions.
Alongside, I would create a “design document” containing guidelines for how to add new content to the documentation: tips on how to structure new sections, general guidelines on what sort of content should be presented in what chapters, etc. The project may also include content rearrangement and a change of hierarchy, if the users find it is needed.
I am currently working on a timeline and action items and researching about the possible shift to another documentation platform.
I am reachable at rachitt01@gmail.com or on the IRC as rachitt_shah, please contact me to suggest changes to the documentation or to provide feedback. We can always benefit from your ideas.
About me, I’m an undergrad studying electronics as my major, and I’m a casual sport programmer as well. I’ve been a product manager and venture capital intern in the past, and done Google Summer of Code with OpenAstronomy.
It is time to announce the participants for in the STE||AR Group’s 2021 Google Summer of Code! We are very proud to announce the names of the 2 students this year who will be funded by Google to work on projects for our group.
These recipients represent the very best of the many excellent proposals that we had to choose from. For those unfamiliar with the program, the Google Summer of Code brings together ambitious students from around the world with open source developers by giving each mentoring organization funds to hire a set number of participants. Students then write proposals, which they submit to a mentoring organization, in hopes of having their work funded.
Below are the students who will be working with the STE||AR Group this summer listed with their mentors and their proposal abstracts.
Participant:
Akhil J Nair, Army Institute Of Technology ( Savitribai Phule Pune University)
Mentors:
Giannis Gonidelis
Hartmut Kaiser
Project: Adapting algorithms to C++ 20 and Ranges TS
I’m Akhil J Nair, a third year undergrad studying computer engineering at AIT, Pune. I’ll be working with the STE||AR group this summer, focusing on the algorithms part of HPX, working on tasks such as adapting the parallel algorithms to C++ 20, adding range overloads, sentinel overloads etc. The algorithms would be adapted to use the tag_invoke customization point mechanism and the C++ 20 overloads will be added according to the C++ 20 Standard. The ranges overloads will also be added as proposed in the C++ extensions to ranges. Adding sentinel overloads and separating the segmented algorithms for the few remaining algorithms will also be done. I’m hoping this would serve as an entry point for me to HPX and the wider world of HPC in general and I look forward to contributing and learning a lot over the coming months.
Participant:
Srinivas Yadav, Keshav Memorial Institute of Technology, Hyderabad, India
Mentors:
Nikunj Gupta
Patrick Diehl
Project: Add vectorization to par_unseq implementations of Parallel Algorithms
I am Srinivas Yadav currently pursuing my Bachelors in Computer Science at KMIT, Hyderabad, India. I will be working with STE | | AR group for HPX this summer in the area of vectorization for parallel algorithms. Current hpx parallel algorithms do not support vectorization. Vectorization allows the algorithms to use the cpu vector registers and hence performance may be improved by utilising most of the cpu resources and allows us to exploit another level of parallelism. This project aims to implement the support for parallel algorithms with explicit vectorization with new `simd` execution policy by using the c++ experimental simd extensions. I hope contributing to HPX would serve me as a stepping stone to the world of HPC and I am looking forward to learning and contributing more over the coming months.
Our Octo-Tiger team here in the STE||AR Group are making waves with their newly published journal article in Monthly Notices of the Royal Astronomical Society, “Octo-Tiger: A New, 3D Hydrodynamic Code for Stellar Mergers That Uses HPX Parallelisation,”
The paper investigates the code performance and precision through benchmark testing. The authors, Dominic C. Marcello, postdoctoral researcher; Sagiv Shiber, postdoctoral researcher; Juhan Frank, professor; Geoffrey C. Clayton, professor; Patrick Diehl, research scientist; and Hartmut Kaiser, research scientist, all at LSU — together with collaborators Orsola De Marco, professor at Macquarie University and Patrick M. Motl, professor at Indiana University Kokomo — compared their results to analytic solutions, when known and other grid-based codes, such as the popular FLASH. In addition, they computed the interaction between two white dwarfs from the early mass transfer through to the merger and compared the results with past simulations of similar systems.
The LSU Physics and Astronomy press release was picked up by almost a dozen computer science and other media sites, including Phys.org, and SciTechDaily. This is an exciting breakthrough as the astrophysics code outlined in the article is able to quickly and accurately simulate the collision of stars.
Understanding stars is fundamental to understanding the smaller planets that orbit them and the large galaxies they inhabit. Stars change over million to billion-year timescales in complex ways, particularly if we consider that many of them are orbited by one or more close companions, with which they exchange mass at different stages during their lives. Recent observations of these mass exchanges as flashes of light, or “transients”, show us a fundamentally new paradigm of stellar evolution, where even well-known phenomena like supernovae need to be understood in a new light. We need to include interacting, multiple stars in our models to explain exploding, outbursting, colliding, and merging stars, to interpret the rapidly increasing number of observations of transients and to ultimately create a new model of stellar evolution.
Octo-Tiger is currently optimized to simulate the merger of well-resolved stars that can be approximated by barotropic structures, such as white dwarfs or main sequence stars. The gravity solver conserves angular momentum to machine precision, thanks to a correction algorithm. This code uses HPX parallelization, allowing the overlap of work and communication and leading to excellent scaling properties, allowing for the computation of large problems in reasonable wall-clock times.
The research outlines the current and planned areas of development aimed at tackling a number of physical phenomena connected to observations of transients.
The video by Sagiv Shriber, found here: https://lsu.app.box.com/s/9g41cbz14l2agk3etx0pxy8ityddknty, shows a simulation of the motion of two white dwarfs in each other’s orbits. We are looking down at these two stars as they begin to merge together.
The collaborative Octo-Tiger project continues, and we look forward to their novel and exciting work in now and in the future.
Octo-Tiger is funded by: National Science Foundation Award1814967
The following computational sources were utilzed to conduct the research: QueenBee2 at Louisiana Optical NetworkInitiative (LONI); BigRed3 at Indiana University was supported by Lilly Endowment, Inc., through its support for the Indiana University Pervasive Technology Institute; and Gadi from the National Computational Infrastructure (NCI Australia), an NCRIS enabled capability supported by the Australian Government.
This year Google is organizing the 3rd annual Google Season of Docs (GSoD). Like Google Summer of Code (GSoC) the program aims to match motivated people with interesting open source projects that are looking for volunteer contributions. GSoD, however, aims to improve open source project documentation, which often tends to get less attention than the code itself. We recognize this all too well in the HPX project. For this reason, we decided to apply for GSoD and can now proudly announce that HPX is one of 30 organizations selected to participate in this year’s GSoD!
This means that we are now looking for motivated people to help us improve our documentation. If you have some prior experience with technical writing, and are interested in working together with us on making the documentation of a cutting-edge open source C++ library the best possible guide for new and experienced users, this is your chance. You can read more about the program on the official GSoD home page. The project proposal that writers would work on can be found here. Writers are welcome to adapt aspects of the project to their specific interests. Our current documentation can be found here.
The deadline for technical writer applications is May 11 anywhere on earth. Apply here! Come talk to us about your ideas and your application on our mailing list, IRC, or Slack. We’d love to hear from you!
The STE||AR Group is honored to be selected as one of the 2021 Google Summer of Code (GSoC) mentor organizations! This program, which pays students over the summer to work on open source projects, has been a wonderful experience for students and mentors alike. This is our 7th summer being accepted by the program!
Interested students can find out more about the details of the program on GSoC’s official website. As a mentor organization we have come up with a list of suggested topics for students to work on, however, any student can write a proposal about any topic they are interested. We find that students who engage with us on IRC (#ste||ar on freenode) or via our mailing list hpx-users@stellar-group.org have a better chance of having their proposals accepted and a better understanding of their project scope. Students may also read through our hints for successful proposals.
If you are interested in working with an international team of developers on the cutting edge of C++ parallel, task-based runtime systems please check us out!